
To the outside world, your organization may seem highly systematized. On the other hand, internal is a collection of data gathered from databases, files, and several other sources. You can use this data to improve and evolve your business, but only if you manage it effectively. You can accomplish this through the consolidation of data!
A company can consolidate data so that it can examine the insights generated by this historical information for guiding future business decisions. In this blog, we will provide an overview of data consolidation as well as some standard data integration techniques.
What is Consolidation of Data?
A data consolidation process involves combining data from different sources, cleaning and verifying it, and storing it in one place, such as a data warehouse. There are multiple sources and formats of data in every business. By consolidating data, it becomes easier to unify it.
By consolidating data, businesses can streamline their data resources, discover patterns, and gain insights from multiple types of data. Users gain a 360-degree view of all their business assets by having all critical data in one place. It also streamlines process execution and simplifies access to information. As a result, data consolidation becomes increasingly important.
Often, data consolidation and data integration are used interchangeably. Both are essential components of data management processes in any organization.
Also Read: What is Decision Automation, and how can you drive it?
Data Consolidation Techniques
Let’s have a look at the data consolidation techniques-
Extract, Transform, and Load (ETL)
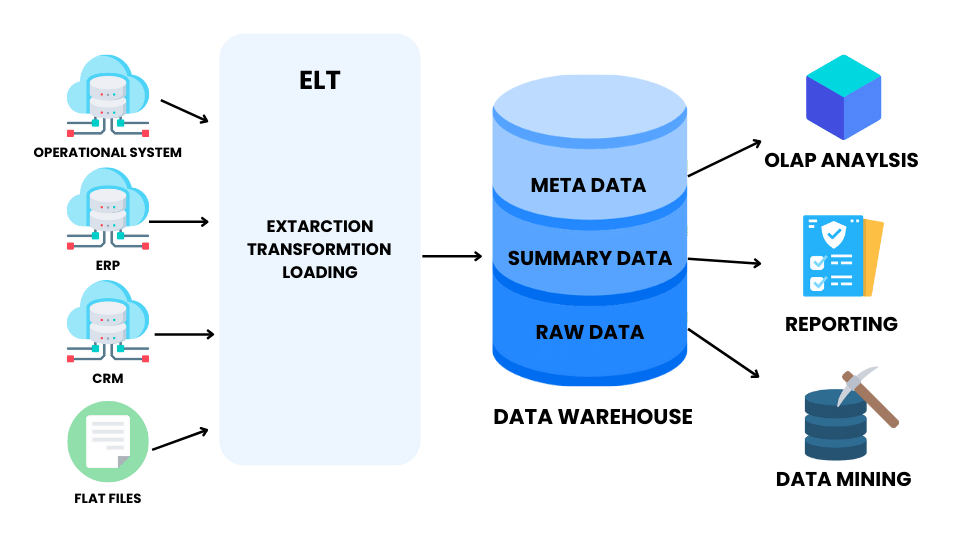
ETL involves extracting data from a source system, transforming it (including cleansing, aggregating, sorting, etc.), and loading it into a target system.
- Extract – The extraction process involves transferring or exporting raw data from different databases or data lakes to a staging area. Here, data quality is ensured through several filtrations through validation.
- Transform – A data transformation involves cleaning, deduplication, joining, and encrypting the data to make it suitable for data analytics. Organizations usually customize transformation processes based on their reporting and analytics requirements.
- Load – After transforming, sorting, cleaning, validating, and preparing the data, load involves moving it from the staging area to the destination data warehouse.
ETL Tools Used
- By hand coding, engineers write scripts to consolidate data from predetermined sources by hand. In smaller jobs with just a few sources, hand-coding can be useful even though it is time-consuming and requires a data engineer.
- To accelerate data consolidation, there are local and cloud-based ETL tools. Implementing these tools automates the ETL process and begins replicating data within minutes. Cloud-based ETL tools are continually updated, tested, and maintained by their providers.
ETL Examples
ETL in Data Warehousing
ETL is a process that helps extract, transform, and load data into a target system. It’s commonly used in data warehousing, where users need to fetch both historical and current data to develop the data warehouse. Data warehouses store a combination of historical and transactional data, often from different heterogeneous systems. So, ETL ensures that this data is properly extracted, transformed, and loaded into the data warehouse.
Data Migration Projects
There are a lot of different ETL tools out there, and they can be helpful in data migration projects. If you’re moving from one database to another, ETL can make the process a lot simpler and less time-consuming. Instead of writing all the code yourself, ETL tools can help you get the job done quickly and efficiently.
Data Integration
Data integration between two organizations can be a challenge, especially when those organizations use different data sources. The ETL process – extract, transform, load – can help make this process easier. Product managers can more easily work with organisational data by extracting data from various sources, transforming it into a common format, and then loading it into a shared repository.
Managing Third Party Data
Different vendors are always used by big organizations for different kinds of application development. This means that no single vendor is managing everything. As an example, let’s take a Telecommunication project where billing is managed by one company and CRM is managed by another company. If the CRM company needs some data from the company that is managing the Billing, then that company will receive a data feed from the other company. To load the data from the feed, an ETL process is used.
Also Read: What is Collaborative Work Management? Top CWM Tools
Data Virtualization
The process of data virtualization combines data from heterogeneous sources without duplicating or moving them. Using it, data operators can view the information in a consolidated, virtual manner.
In contrast to an ETL process, data stays in its place but can be retrieved virtually by front-end solutions like apps, dashboards, and portals without knowing where it is stored.
Data Virtualization differs from virtualized Storage and Logical Data Warehouses. Moreover, centralized access control alleviates data governance issues. It provides better data security and real-time reporting capabilities.
What is the difference between Data Visualization and Data Virtualization?
Data visualization is the process of displaying data in charts, graphs, maps, reports, 3D images, and so on. Data visualization is made possible through data virtualization, which is the process of pulling data from multiple sources and creating a single, cohesive data set. Data visualization is a quick, easy way to convey concepts in a way that everyone can understand. Data virtualization, on the other hand, increases productivity by making available reusable logical data views into a single data set.
Data visualization is used in many industries, including the military (to understand geography and climate with bar charts), the financial sector (investment strategies), and real estate (to see comparable home prices in neighborhoods on a map). The use of data virtualization is widespread in healthcare (driving innovation), manufacturing (optimizing farms and logistics), and financial services (managing fixed-risk liabilities).
Data Warehousing
Data warehousing involves integrating data from disparate sources and storing it in a centralized location. As a result, it facilitates reporting, business intelligence, and other ad hoc queries. With relevant data clustered together, it provides a broad, integrated view of all data assets.
Companies have also implemented Streaming Analytics due to the superior performance of Data Warehousing. Lastly, a data warehouse helps an organization maintain uniformity in data.
There are three tiers in a data warehouse architecture:
- Tier 1: Front-end client that displays analysis and reporting results.
- Tier 2: Contains data access and analysis engines.
- Tier 3: The bottom tier consists of the database server, which loads and stores data.
Data Warehousing Examples
- For example, data warehousing is used in the investment and insurance sectors to analyze market trends and customer data. In both the forex and stock markets, data warehouses play a crucial role because even a single point difference can result in massive losses.
- Distribution and marketing departments use DWHs to keep track of items, review pricing policies, monitor promotional offers, and analyze customer buying trends. For business intelligence and forecasting, retail chains usually incorporate EDW systems.
- Healthcare providers, research labs, and other medical units use DWHs to forecast outcomes, generate treatment reports, and share data. Healthcare systems rely on EDWs because the latest, most up-to-date treatment information is crucial.
Why is Data Consolidation essential?
Data consolidation helps businesses break down information barriers and data silo problems to make data more accessible and useful. By consolidating data into one integrated place, companies gain better control over their data. The ETL process is used for data consolidation. It ensures high-speed analytics as the data is ready to go.
Data analytics helps companies make better decisions and reduce operational costs. By consolidating all your company’s data into one place, you will be able to analyze it quickly and easily. Let’s have a look at the following benefits of consolidating data.
- Reduced cost
- Better security
- Good Decision-Making

Challenges Associated with the Consolidation of Data
Consolidation of data presents challenges such as:
A limited number of resources
Data engineers have limited resources since hand-coding consolidation techniques require them to write code, manage the process, and write code each time a new data source is added. It takes longer to process data when there are more sources and types of data involved.
Various locations
In many businesses, data can’t be stored in one physical location, so it must be managed and secured in several locations. It takes time and bandwidth to retrieve that outlying data and combine it with local data sources.
A security system
Storing data in another location can increase the risk of breaches and hacks. When businesses have scattered datasets, it can be challenging to comply with security policies since they may also need to adhere to their industry regulations.
Amount of time
As part of their daily tasks, internal IT teams typically have limited time to configure, assess, maintain, and examine on-site equipment and hardware. It may not be possible for the team to spend additional time managing data consolidation.
How to Consolidate Data: Best Practices
Organizations must carefully plan and execute data consolidation projects. Consolidating data effectively requires these best practices:
Data Transformation
Make sure the data types and the consolidation target are compatible. This means that to rectify the differences, and the data must be transformed.
Make copies of your data
Data lineage refers to the method for tracing and referencing the origin, transformation, and consolidation of data. By analyzing this data, a company can demonstrate compliance with regulations or gain insight into future decisions by retracing its steps.
The standardization of character set conversions
In applications that accept single-byte characters, characters can be converted when they are used. The processing tools, however, might not recognize that the data is in a different format, resulting in errors. When consolidating data, standardized character set conversions result in more accurate and reliable results.
Power of Data Consolidation for Digital-First Organizations
Organizations are inundated with vast amounts of data from various sources. The key to leveraging this data effectively lies in consolidation – the process of bringing scattered data together into a unified and accessible format. By consolidating data, organizations can gain valuable insights, improve decision-making, and fuel innovation. This complete guide explores the importance of data consolidation in a digital-first organization and provides practical strategies and best practices to streamline the process. From data integration techniques to data governance frameworks, this guide empowers organizations to harness the full potential of their data, driving success in the digital era.
Conclusion
Big Data is an emerging asset for many businesses. It provides them with valuable information about customers, competitors, market trends, and other important aspects of their industry. However, there are challenges associated with managing big data.
One challenge is to consolidate all the different types of data into a single place. Another challenge is to extract useful information from the data. Tools that help in the consolidation of data save the day! They offer a fast way to move data from databases or SaaS applications to your data warehouse to be visualized in analytics tools.
Frequently Asked Questions(FAQs)
Q. How do you consolidate data?
Q. Why is data consolidation important?
Data consolidation is vital as it centralizes scattered information, improving accuracy and accessibility. It streamlines analysis, enabling better decision-making, and enhances data security. Ultimately, it optimizes operations and supports informed, data-driven strategies.
Q. What are Data consolidation tools and techniques?
Data consolidation tools and techniques include ETL tools, data integration platforms, data warehouses, APIs, MDM tools, data virtualization, no-code/low-code platforms, custom scripting, cloud-based services, and data governance tools. These solutions enable organizations to merge, integrate, and centralize data from various sources, enhancing data quality, accessibility, and analysis for improved decision-making.
Q. What is data consolidation with an example?
Data consolidation refers to the process of gathering and merging data from multiple sources into a unified and central repository. It aims to create a comprehensive dataset for analysis, reporting, and decision-making.
Example: In a retail company, sales data may be stored in separate databases for different store locations. Data consolidation involves extracting sales information from all these databases and merging it into a single, centralized database. This consolidated dataset can then be used for various purposes, such as sales performance analysis, inventory management, and financial reporting, providing a holistic view of the company’s operations.
Q. What are the benefits of data consolidation?
The benefits of data consolidation include improved data accuracy, streamlined analysis, enhanced decision-making, reduced redundancy, and simplified data management.
Related Post



Login
Please login to comment
0 Comments
Oldest
Recent Posts






![]()

![]()
- Download the App






